31、丑数
32、第一个只出现过一次的字符
33、数组中的逆序对
34、两个链表的第一个公共结点
35、数字在排序数组中出现的次数
36、二叉树的深度
37、数组中只出现一次的数字
38、和为S的两个数字
39、翻转单词顺序
40、左旋字符串
31、丑数
题目:我们把只包含因子2、3 和5 的数称作丑数(Ugly Number)。求从小到大的顺序的第1500个丑数。
举例说明:例如6、8 都是丑数,但14 不是,它包含因子7。习惯上我们把1 当做第一个丑数。
思路:只计算丑数,而不在非丑数的整数上花费时间。根据丑数的定义,丑数应该是另一个丑数乘以2、3或者5的结果(1除外)。因此我们可以创建一个数组,里面的数字是排好序的丑数。里面的每一个丑数是前面的丑数乘以2、3或者5得到的。这种思路的关键在于怎样确保数组里面的丑数是排好序的。我们假设数组中已经有若干个丑数,排好序后存在数组中。我们把现有的最大丑数记做M。现在我们来生成下一个丑数,该丑数肯定是前面某一个丑数乘以2、3或者5的结果。我们首先考虑把已有的每个丑数乘以2。在乘以2的时候,能得到若干个结果小于或等于M的。由于我们是按照顺序生成的,小于或者等于M肯定已经在数组中了,我们不需再次考虑;我们还会得到若干个大于M的结果,但我们只需要第一个大于M的结果,因为我们希望丑数是按从小到大顺序生成的,其他更大的结果我们以后再说。我们把得到的第一个乘以2后大于M的结果,记为M2。同样我们把已有的每一个丑数乘以3和5,能得到第一个大于M的结果M3和M5。那么下一个丑数应该是M2、M3和M5三个数的最小者。前面我们分析的时候,提到把已有的每个丑数分别都乘以2、3和5,事实上是不需要的,因为已有的丑数是按顺序存在数组中的。对乘以2而言,肯定存在某一个丑数T2,排在它之前的每一个丑数乘以2得到的结果都会小于已有最大的丑数,在它之后的每一个丑数乘以2得到的结果都会太大。我们只需要记下这个丑数的位置,同时每次生成新的丑数的时候,去更新这个T2。对乘以3和5而言,存在着同样的T3和T5。
int Min(int number1, int number2, int number3)
{
int min = (number1 < number2) ? number1 : number2;
min = (min < number3) ? min : number3;
return min;
}
int findUglyNum2(int index)
{
int *pUglyNumbers = new int[index];
pUglyNumbers[0] = 1;
int nextUglyIndex = 1;
int *pMultiply2 = pUglyNumbers;
int *pMultiply3 = pUglyNumbers;
int *pMultiply5 = pUglyNumbers;
while(nextUglyIndex < index)
{
int min = Min(*pMultiply2*2, *pMultiply3*3,*pMultiply5*5);
pUglyNumbers[nextUglyIndex] = min;
while(*pMultiply2*2 <= pUglyNumbers[nextUglyIndex])
++pMultiply2;
while(*pMultiply3*3 <= pUglyNumbers[nextUglyIndex])
++pMultiply3;
while(*pMultiply5*5 <= pUglyNumbers[nextUglyIndex])
++pMultiply5;
++nextUglyIndex;
}
int ugly = pUglyNumbers[nextUglyIndex - 1];
delete[] pUglyNumbers;
return ugly;
}
int main()
{
time_t begin2,end2;
begin2=clock();
cout<<findUglyNum2(1500)<<endl;
end2=clock();
cout<<"runtime: "<<double(end2-begin2)/CLOCKS_PER_SEC<<endl;
return 0;
}
32、第一个只出现过一次的字符
题目:在字符串中找出第一个只出现一次的字符。
思路:采用一个数组记录出现的次数然后再遍历该数组
#include "stdafx.h"
#include <iostream>
using namespace std;
/*
字符char是一个长度为8的数据类型,因此总共有256种可能,于是我们创建一个长度为256的数组
每个字母根据其ASCII码值作为数组的下标对应数组的一个数字,而数组中存储的是每个字符出现的次数
*/
char FindFirstChar(char* pString)
{
if(pString == NULL)
return '\0';
const int N = 256;
int b[N];
for(int i = 0; i < N; ++i)
{
b[i] = 0;
}
char* p = pString;
while (*p != '\0')
{
b[*(p++)]++;
}
p = pString;
while (*p != '\0')
{
if (b[*p] == 1)
{
return *p;
}
++p;
}
return '\0';
}
int main()
{
char* pString = "abcddeeff";
char c = FindFirstChar(pString);
cout<<c<<endl;
getchar();
return 0;
}
33、数组中的逆序对
题目:在数组中的两个数字如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。输入一个数组,求出这个数组中的逆序对的总数。
举例分析:例如在数组{7, 5, 6, 4 }中, 一共存在5 个逆序对,分别是(7, 6)、(7,5),(7, 4)、(6, 4)和(5, 4)。
思路:
1)总体的意思就是将数组分成两段,首先求段内的逆序对数量,比如下面两段代码就是求左右两端数组段内的逆序对数量
inversions+=InversePairsCore(arry,start,mid,temp);//找左半段的逆序对数目
inversions+=InversePairsCore(arry,mid+1,end,temp);//找右半段的逆序对数目
(2)然后求段间的逆序对数量,如下面的代码
inversions+=MergeArray(arry,start,mid,end,temp);//在找完左右半段逆序对以后两段数组有序,然后找两段之间的逆序对。最小的逆序段只有一个元素。
(3)然后在求段间逆序对的时候,我们分为arry[start…mid]和arry[mid+1…end],然后设置两个指针ij分别指向两段数组的末尾元素,也就是i=mid,j=end。然后比较arry[i]和arry[j],
- 如果arry[i]>arry[j],因为两段数组都是有序的,所以arry[i]>arry[mid+1…j],这些都是逆序对,我们统计出的逆序对为j-(mid+1)+1=j-mid。并且将大数arry[i]放入临时数组temp[]当中,i往前移动
- 如果arry[i]<arry[j],则将大数arry[j]放入temp[]中,j往前移。
#include<iostream>
#include<stdlib.h>
using namespace std;
void printArray(int arry[],int len)
{
for(int i=0;i<len;i++)
cout<<arry[i]<<" ";
cout<<endl;
}
int MergeArray(int arry[],int start,int mid,int end,int temp[])//数组的归并操作
{
//int leftLen=mid-start+1;//arry[start...mid]左半段长度
//int rightLlen=end-mid;//arry[mid+1...end]右半段长度
int i=mid;
int j=end;
int k=0;//临时数组末尾坐标
int count=0;
//设定两个指针ij分别指向两段有序数组的头元素,将小的那一个放入到临时数组中去。
while(i>=start&&j>mid)
{
if(arry[i]>arry[j])
{
temp[k++]=arry[i--];//从临时数组的最后一个位置开始排序
count+=j-mid;//因为arry[mid+1...j...end]是有序的,如果arry[i]>arry[j],那么也大于arry[j]之前的元素,从a[mid+1...j]一共有j-(mid+1)+1=j-mid
}
else
{
temp[k++]=arry[j--];
}
}
cout<<"调用MergeArray时的count:"<<count<<endl;
while(i>=start)//表示前半段数组中还有元素未放入临时数组
{
temp[k++]=arry[i--];
}
while(j>mid)
{
temp[k++]=arry[j--];
}
//将临时数组中的元素写回到原数组当中去。
for(i=0;i<k;i++)
arry[end-i]=temp[i];
printArray(arry,8);//输出进过一次归并以后的数组,用于理解整体过程
return count;
}
int InversePairsCore(int arry[],int start,int end,int temp[])
{
int inversions = 0;
if(start<end)
{
int mid=(start+end)/2;
inversions+=InversePairsCore(arry,start,mid,temp);//找左半段的逆序对数目
inversions+=InversePairsCore(arry,mid+1,end,temp);//找右半段的逆序对数目
inversions+=MergeArray(arry,start,mid,end,temp);//在找完左右半段逆序对以后两段数组有序,然后找两段之间的逆序对。最小的逆序段只有一个元素。
}
return inversions;
}
int InversePairs(int arry[],int len)
{
int *temp=new int[len];
int count=InversePairsCore(arry,0,len-1,temp);
delete[] temp;
return count;
}
void main()
{
//int arry[]={7,5,6,4};
int arry[]={1,3,7,8,2,4,6,5};
int len=sizeof(arry)/sizeof(int);
//printArray(arry,len);
int count=InversePairs(arry,len);
//printArray(arry,len);
//cout<<count<<endl;
system("pause");
}
34、两个链表的第一个公共结点
题目:输入两个链表,找出它们的第一个公共结点。
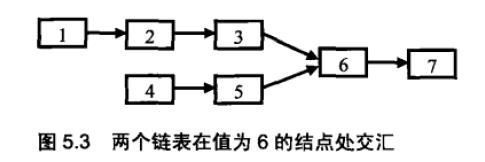
思路:我们可以先遍历一次得到它们的长度分别为5 和4, 也就是较长的链表与较短的链表相比多一个结点。第二次先在长的链表上走1 步,到达结点2。接下来分别从结点2 和结点4 出发同时遍历两个结点, 直到找到它们第一个相同的结点6,这就是我们想要的结果。
/*
获取链表的长度
*/
int getLength(pNode pHead)
{
int len = 0;
pNode pCur = pHead;
while(pCur != NULL)
{
len++;
pCur = pCur->next;
}
return len;
}
/*
求两个链表的第一个公共节点
*/
pNode FindFirstCommonNode(pNode pHead1,pNode pHead2)
{
if(pHead1==NULL ||pHead2==NULL)
return NULL;
int len1 = getLength(pHead1);
int len2 = getLength(pHead2);
pNode pListLong = pHead1;
pNode pListShort = pHead2;
int distance = len1-len2;
int shortLength = len2;
if(len1 < len2)
{
pListLong = pHead2;
pListShort = pHead1;
distance = len2-len1;
shortLength = len1;
}
int i;
for(i=0;i<distance;i++)
pListLong = pListLong->next;
for(i=0;i<shortLength;i++)
{
if(pListLong->data == pListShort->data)
break;
pListLong = pListLong->next;
pListShort = pListShort->next;
}
return pListLong;
}
35、数字在排序数组中出现的次数
题目:统计一个数字:在排序数组中出现的次数。
举例说明:例如输入排序数组{ 1, 2, 3, 3, 3, 3, 4, 5}和数字3 ,由于3 在这个数组中出现了4 次,因此输出4 。
思路:二分法找到第一个k和最后一个K
如何用二分查找算法在数组中找到第一个k,二分查找算法总是先拿数组中间的数字和k作比较。如果中间的数字比k大,那么k只有可能出现在数组的前半段,下一轮我们只在数组的前半段查找就可以了。如果中间的数字比k小,那么k只有可能出现在数组的后半段,下一轮我们只在数组的后半乓查找就可以了。如果中间的数字和k 相等呢?我们先判断这个数字是不是第一个k。如果位于中间数字的前面一个数字不是k,此时中间的数字刚好就是第一个k。如果中间数字的前面一个数字也是k,也就是说第一个k肯定在数组的前半段, 下一轮我们仍然需要在数组的前半段查找。 同样的思路在排序数组中找到最后一个k。如果中间数字比k大,那么k只能出现在数组的前半段。如果中间数字比k小,k就只能出现在数组的后半段。如果中间数字等于k呢?我们需要判断这个k是不是最后一个k,也就是中间数字的下一个数字是不是也等于k。如果下一个数字不是k,则中间数字就是最后一个k了:否则下一轮我们还是要在数组的后半段中去查找。
#include<iostream>
using namespace std;
int searchFirstEqual(int a[],int n,int key)
{
int low=0,high=n-1,mid;
while(low<=high)
{
mid=(low+high)>>1;
if(a[mid]>=key)
high=mid-1;
else
low=mid+1;
}
if(low<n && a[low]==key) return low;
else
return -1;
}
int searchLastEqual(int arr[],int n,int key)
{
int low=0,high=n-1,mid;
while(low<=high)
{
mid=low+(high-low)/2;
if(arr[mid]<=key)
{
low=mid+1;
}
else
{
high=mid-1;
}
}
if(high>=0 && arr[high]==key) return high;
else
return -1;
}
int main()
{
int a[]={1,3,3,3,5,6};
int n=sizeof(a)/sizeof(a[0]);
int start=searchFirstEqual(a,n,3);
int end=searchLastEqual(a,n,3);
cout<<start<<endl;
cout<<end<<endl;
cout<<end-start+1<<endl;
}
36、二叉树的深度
题目:输入一颗二叉树的根结点,求该树的深度
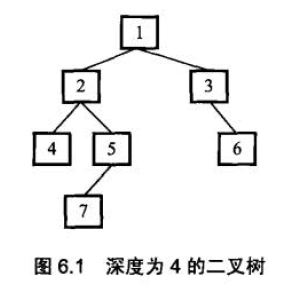
思路:依次选择最深的左右子树, 然后递归加1.
int TreeDepth(BinaryTreeNode* pRoot) {
if (pRoot == NULL)
return 0;
int nLeft = TreeDepth(pRoot->m_pLeft);
int nRight = TreeDepth(pRoot->m_pRight);
return (nLeft>nRight) ? (nLeft+1):(nRight+1);
}
37、数组中只出现一次的数字
题目:一个整型数组里除了两个数字之外,其他的数字都出现了两次,请写程序找出这两个只出现一次的数字。要求时间复杂度是O(n),空间复杂度是O(1)。
举例说明:例如输入数组{2, 4, 3, 6, 3, 2, 5 },因为只有4 、6 这两个数字只出现一次,其他数字都出现了两次,所以输出4和6 。
思路:题目为什么要强调有一个数字出现一次,其他的出现两次?我们想到了异或运算的性质:任何一个数字异或它自己都等于0。也就是说,如果我们从头到尾依次异或数组中的每一个数字,那么最终的结果刚好是那个只出现依次的数字,因为那些出现两次的数字全部在异或中抵消掉了。
有了上面简单问题的解决方案之后,我们回到原始的问题。如果能够把原数组分为两个子数组。在每个子数组中,包含一个只出现一次的数字,而其他数字都出现两次。如果能够这样拆分原数组,按照前面的办法就是分别求出这两个只出现一次的数字了。
我们还是从头到尾依次异或数组中的每一个数字,那么最终得到的结果就是两个只出现一次的数字的异或结果。因为其他数字都出现了两次,在异或中全部抵消掉了。由于这两个数字肯定不一样,那么这个异或结果肯定不为0,也就是说在这个结果数字的二进制表示中至少就有一位为1。我们在结果数字中找到第一个为1的位的位置,记为第N位。现在我们以第N位是不是1为标准把原数组中的数字分成两个子数组,第一个子数组中每个数字的第N位都为1,而第二个子数组的每个数字的第N位都为0。
现在我们已经把原数组分成了两个子数组,每个子数组都包含一个只出现一次的数字,而其他数字都出现了两次。因此到此为止,所有的问题我们都已经解决。
void FindNumsAppearOnce(vector<int> data,int* num1,int *num2) {
if(data.size()<2) return ;
int size=data.size();
int temp=0;
for(int i=0;i<size;i++)//对数组中每个数字做异或
temp=temp^data[i];
if(temp==0) return ;
int index=0;
while((temp&1)==0)//在整数temp的二进制表示中找到最右边是1的位
{
temp=temp>>1;
++index;
}
//根据数组的倒数第index位是否为1,将数组划分为两个子数组,并分别对两个子数组进行求异或,得到num1 和num2
*num1=*num2=0;
for(int i=0;i<size;i++)
{
if(IsBit(data[i],index))
*num1^=data[i];
else
*num2^=data[i];
}
}
//判断在num的二进制表示中从右边起的index位是不是1
bool IsBit(int num,int index)
{
num=num>>index;
return (num&1);
}
38、和为S的两个数字
题目:输入一个递增排序的数组和一个数字s,在数组中查找两个数,得它们的和正好是s。如果有多对数字的和等于s,输出任意一对即可。例如输入数组{1 、2 、4、7 、11 、15 }和数字15. 由于4+ 11 = 15 ,因此输出4 和11 。
思路:数列满足递增,设两个头尾两个指针i和j,
若ai + aj == sum,就是答案(相差越远乘积越小)
若ai + aj > sum,aj肯定不是答案之一(前面已得出 i 前面的数已是不可能),j -= 1
若ai + aj < sum,ai肯定不是答案之一(前面已得出 j 后面的数已是不可能),i += 1
typedef vector<int> vi;
class Solution {
public:
vi FindNumbersWithSum(const vi& a,int sum) {
vi res;
int n = a.size();
int i = 0, j = n - 1;
while(i < j){
if(a[i] + a[j] == sum){
res.push_back(a[i]);
res.push_back(a[j]);
break;
}
while(i < j && a[i] + a[j] > sum) --j;
while(i < j && a[i] + a[j] < sum) ++i;
}
return res;
}
};
39、翻转单词顺序
题目:输入一个英文句子,翻转句子中单词的顺序,但单词内字啊的顺序不变。为简单起见,标点符号和普通字母一样处理。
举例:例如输入字符串”I am a student. ”,则输出”student. a am I”。
思路一:左往右遍历字符串,逐个拼接每个单词即可
#include <iostream>
#include <string>
using namespace std;
string ReverseSentence(string str)
{
string res = "", tmp = "";
for(unsigned int i = 0; i < str.size(); ++i)
{
// 遇到空格
if(str[i] == ' ')
{
res = " " + tmp + res;
cout << tmp << "\n" <<endl;
tmp = "";
}
else
{
tmp += str[i];
}
}
// 最后一个字符
if(tmp.size())
res = tmp + res;
return res;
}
int main(void)
{
string str = "student. a am I";
cout<<ReverseSentence(str)<<endl;
return 0;
}
思路二:将整个字符串翻转,然后定位到每个单词再次翻转一下
40、左旋字符串
题目:字符串的左旋转操作是把字符串前面的若干个字符转移到字符串的尾部。请定义一个函数实现字符串左旋转操作的功能。
举例:比如输入字符串”abcdefg”和数字2,该函数将返回左旋转2 位得到的结”cdefgab”。
思路:分为两部分,分别翻转成为“bagfedc”,在整体翻转
#include <stdio.h>
void reverse(char a[],int l,int r){
int i = l;
int j = r;
for (; i < j ; i++,j--) {
char temp = a[i];
a[i] = a[j];
a[j] = temp;
}
printf("==%s\n",a);
}
void left_rever(char a[],int leng,int n){
reverse(a,0,n-1);
reverse(a,n,leng-1);
reverse(a,0,leng-1);
printf("%s",a);
}
int main(void)
{
char a[] = "abcdefg";
left_rever(a,7,2);
return 0;
}
####