1、redisServer
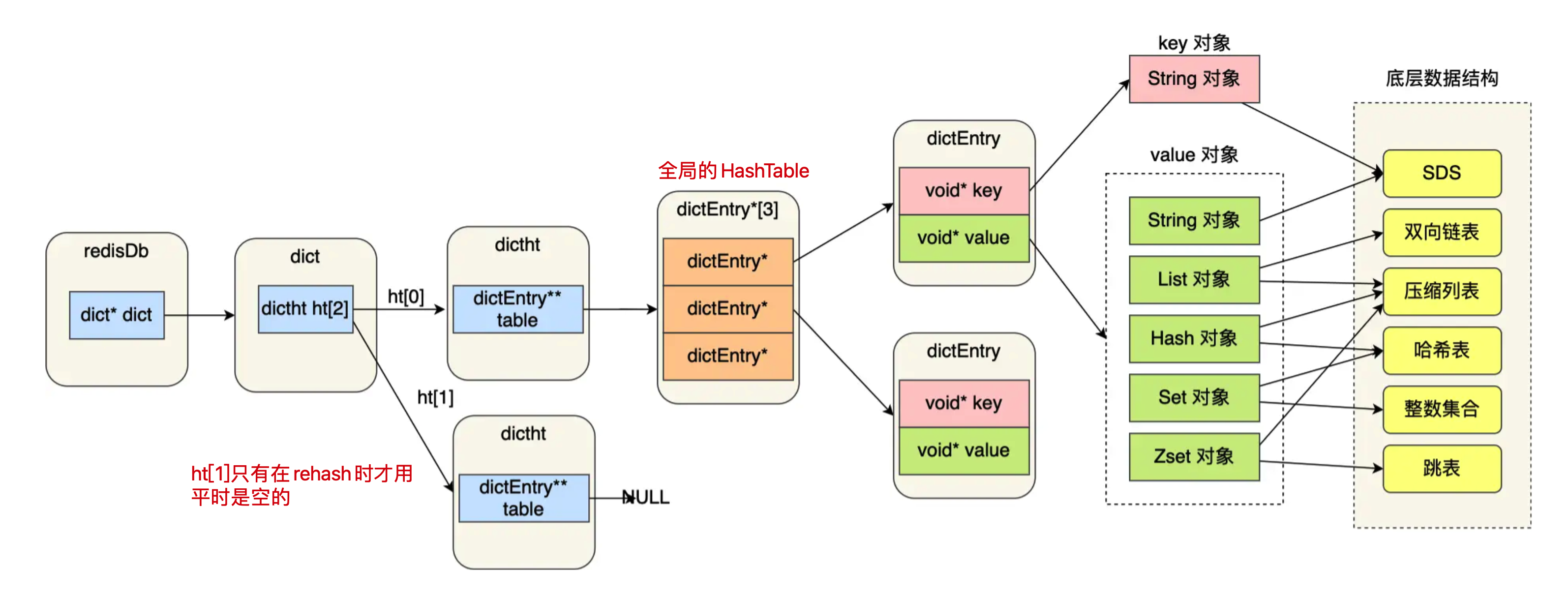
redis 的数据是保存在 redisServer 中的 redisDb 结构中。
Redis 服务器将绝大部分的信息都保存在 server.h/redisServer。
struct redisServer {
// ...
redisDb *db; // 数据库列表
// ...
int dbnum; // 数据库数量
// ...
}
- db 中每个redisDb结构代表一个数据库,每个db是相互独立的。
- dbnum 属性的值由服务器配置的 database 选项决定,默认情况下,该选项的值为16,所以Redis服务器默认会创建16个数据库。
- 每次访问数据时先用SELECT index命令切换数据库然后再操作。
- 实际上,我们只会在redisDb[0]上进行操作。
- 之所以会默认定义这么多db,是最初设计时考虑不同数据存在不同db上,但最后觉得很鸡肋,由于要保持向下兼容,所以就保留了这个功能。虽然实际生产中Redis实例很少会用到多个DB,但每个DB大概1m左右也不是十分耗费资源,所以无伤大雅
2、redisDb-dict
/* Redis数据库结构体 */
typedef struct redisDb {
// 数据库键空间,存放着所有的key-value对
dict *dict;
// 键的过期时间
dict *expires;
int id;
} redisDb;
可以看到,redisDb 的 dict 字典属性保存了数据库中的所有key-value,我们将这个字典称为键空间(key space),增删改查也就是对 dict 的操作而已。
示例
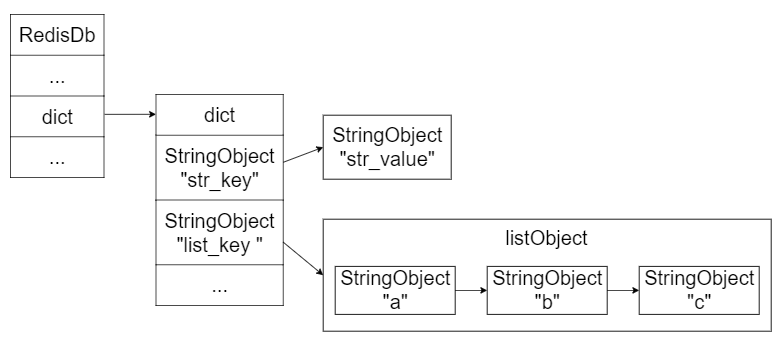
如果,我们在redis中执行以下命令:
redis > SET str_key str_value
OK
redis > RPUSH list_key a b c
(integer) 3
redis新添加的key-value在dict里是这样的一个结构
3、redisDb-expires
redisDb 中的 expires 属性保存了所有 key 的过期时间,我们姑且就称它为过期字典吧。
- 过期字典中的键,是一个指针,指向了真实数据的 key,不会浪费空间多保存一次
- 过期字典中的值,存的是具体的过期时间点,精确到毫秒的时间戳
一个 key 过期时间到了之后,是如何进行删除的呢?Redis 使用了一下两种策略:惰性删除、定期删除
惰性删除
惰性删除策略指的是:key 在过期之后,没有立即删除,而是在读写 key 的时候,才对过期的 key 进行删除。
代码实现在 db.c/expireIfNeeded 方法中。所有 key 的读写之前,都会先调用 expireIfNeeded 对 key 进行检查,如果已过期,则删除。
定期删除
定期删除策略指的是:Redis 每隔一段时间,随机从数据库中取出一定量的 key 进行检查,如果已过期,则进行删除。
代码实现在 expire.c/activeExpireCycle 方法中。
删除的步骤:
- 从过期字典中随机 20 个 key
- 删除这 20 个 key 中已经过期的 key
- 如果过期的 key 比率超过 1/4,那就重复步骤 1
为什么只是随机挑 一些 key 呢?因为如果把所有 key 都遍历一遍,那这个性能肯定是不能接受的!所以还需要配合惰性删除。
总结
过期数据的清除从来不容易,为每一条key设置一个timer,到点立刻删除的消耗太大,每秒遍历所有数据消耗也大,Redis使用了一种相对务实的做法: 当client主动访问key会先对key进行超时判断,过时的key会立刻删除。 如果clien永远都不再get那条key呢? 它会在Master的后台,每秒10次的执行如下操作: 随机选取100个key校验是否过期,如果有25个以上的key过期了,立刻额外随机选取下100个key(不计算在10次之内)。可见,如果过期的key不多,它最多每秒回收200条左右,如果有超过25%的key过期了,它就会做得更多,但只要key不被主动get,它占用的内存什么时候最终被清理掉只有天知道。
4、dictht
dictht是redisDb-dict里面存放key-value的全局哈希表,有两个,一个是实际存放key-value的,另外一个是用于rehash。
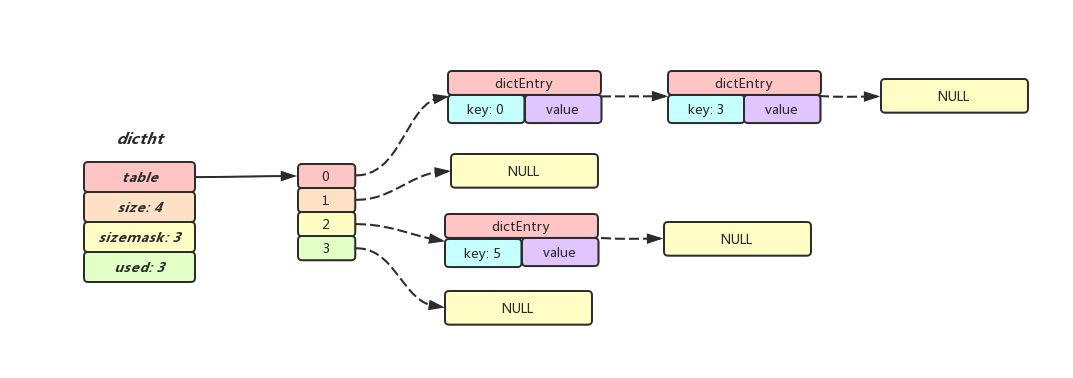
ditctht 结构,表示哈希表的结构,结构里存放了哈希表数组,数组中的每个元素都是指向一个哈希表节点结构(dictEntry)的指针;
typedef struct dictht {
// HashTable数组,数组的每个元素都是个指向dictEntry结构的指针
dictEntry **table;
// HashTable的大小
unsigned long size;
// HashTable大小掩码,总是等于size - 1, 通常用来计算索引
unsigned long sizemask;
// 已经使用的节点数,实际上就是HashTable中已经存在的dictEntry数量
unsigned long used;
} dictht;
5、dictEntry
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 用来指向与当前dictEntry在同一个索引的下一个dictEntry
struct dictEntry *next;
} dictEntry;
dictEntry是Dictht中结点的表现形式, 每个dictEntry都保存着一个键值对
- key属性指向键值对的键对象,
- v属性则保存着键值对的值, Redis采用了联合体来定义v, 使键值对的value既可以存储一个指针, 也可以存储有符号/无符号整形数据,甚至可以存储浮点形数据, Redis使用联合体的形式来存储键值对的值可以让内存使用更加精细灵活,
- 另外, 既然是HashTable, 不可避免会发生两个键不同但是计算出来存放索引相同的情况, 为了解决Hash冲突的问题, dictEntry还有一个next属性, 用来指向与当前dictEntry在同一个索引的下一个dictEntry.多个 dictEntry 可以通过 next 指针串连成链表, 从这里可以看出, dictht 使用链式寻址法来解决hash冲突: 当多个不同的键拥有相同的哈希值时,哈希表用一个链表将这些键连接起来。
- void * key 和 void * value 指针指向的是 Redis 对象,Redis 中的每个对象都由 redisObject 结构表示
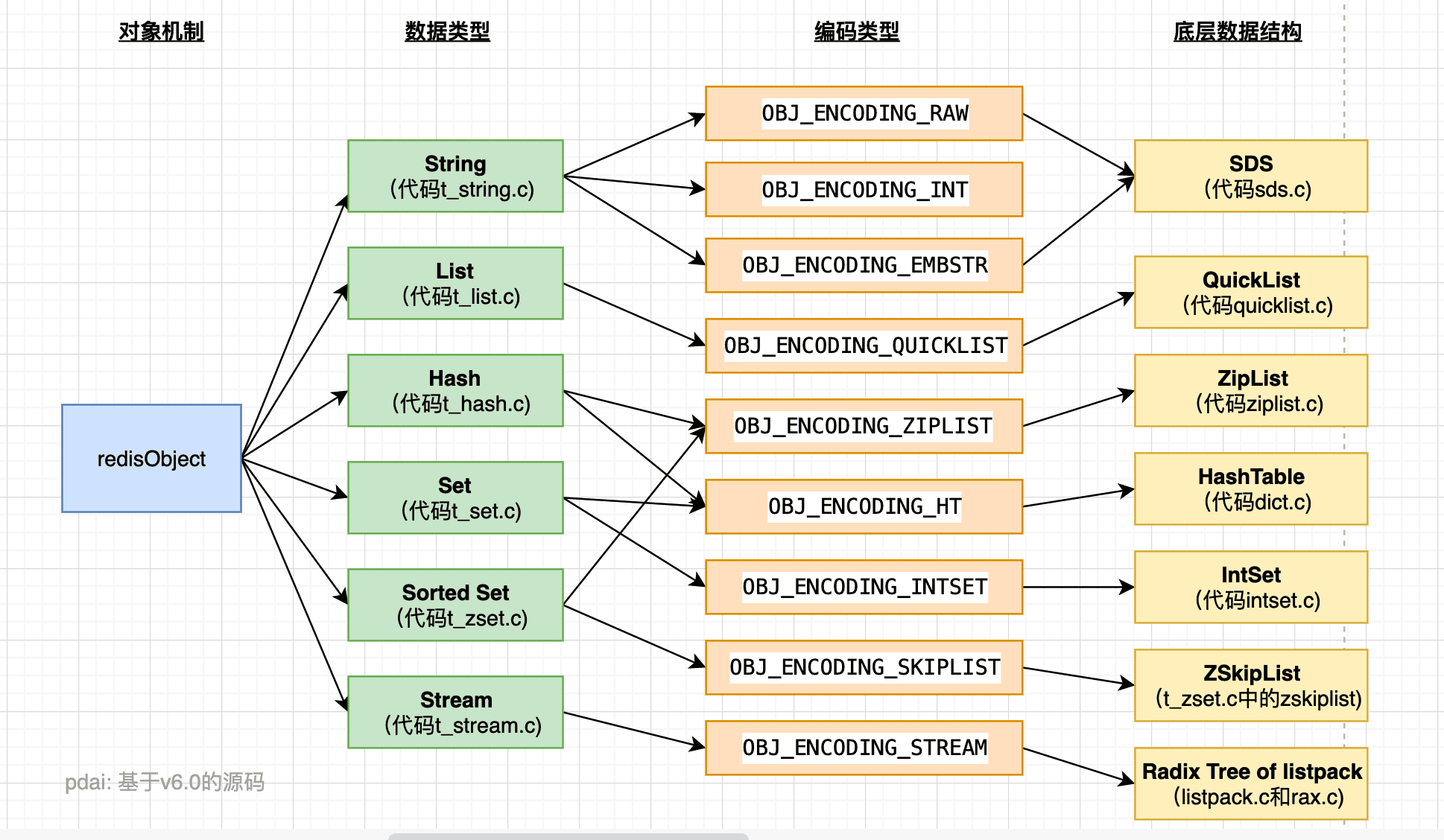
6、Redis对象(RedisObject)
dictEntry里面的void * key 和 void * value 指针指向的是 Redis 对象,Redis 中的每个对象都由 redisObject 结构表示。
typedef struct redisObject {
// 数据类型,取值范围为String、List、Set、SortedSet、Hash等五种类型
unsigned type:4;
// 对齐位
unsigned notused:2;
// 物理编码方式,同一种数据类型可能有不同的编码方式
unsigned encoding:4;
// LRU 时间(相对于 server.lruclock)
unsigned lru:22;
// 引用计数,C语言来管理自己的内存,防止内存溢出。
int refcount;
// 指向真正数据,如果是整型值等,则直接存储,如果是很长的字符串,则存放指向数据的地址。
void *ptr;
} robj;
type: 记录了对象所保存的值的类型,它的值可能是以下常量的其中一个(定义位于 redis.h):
#define OBJ_STRING 0 // 字符串
#define OBJ_LIST 1 // 列表
#define OBJ_SET 2 // 集合
#define OBJ_ZSET 3 // 有序集
#define OBJ_HASH 4 // 哈希表
#define OBJ_MODULE 5 /* Module object. */
#define OBJ_STREAM 6 /* Stream object. */
encoding 记录了对象所保存的值的编码,它的值可能是以下常量的其中一个(定义位于 redis.h):
#define REDIS_ENCODING_RAW 0 // 编码为字符串
#define REDIS_ENCODING_INT 1 // 编码为整数
#define REDIS_ENCODING_HT 2 // 编码为哈希表
#define REDIS_ENCODING_ZIPMAP 3 // 编码为 zipmap
#define REDIS_ENCODING_LINKEDLIST 4 // 编码为双端链表
#define REDIS_ENCODING_ZIPLIST 5 // 编码为压缩列表
#define REDIS_ENCODING_INTSET 6 // 编码为整数集合
#define REDIS_ENCODING_SKIPLIST 7 // 编码为跳跃表
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */
#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */
ptr 是一个指针,指向实际保存值的数据结构,这个数据结构由 type 属性和 encoding 属性决定。
举个例子,如果一个 redisObject 的 type 属性为 REDIS_LIST , encoding 属性为 REDIS_ENCODING_LINKEDLIST ,那么这个对象就是一个 Redis 列表,它的值保存在一个双端链表内,而 ptr 指针就指向这个双端链表;
另一方面,如果一个 redisObject 的 type 属性为 REDIS_HASH , encoding 属性为 REDIS_ENCODING_ZIPMAP ,那么这个对象就是一个 Redis 哈希表,它的值保存在一个 zipmap 里,而 ptr 指针就指向这个 zipmap ;诸如此类。
下图展示了 redisObject 、Redis 所有数据类型、以及 Redis 所有编码方式(底层实现)三者之间的关系: